Published 2026-05-18 by Sai
Google Health Coach Invented a Workout. Here's Why AI Fitness Apps Do This.
On May 14, 2026, Will Sattelberg of 9to5Google published a hands-on review of Google Health Coach. The coach told him he had completed a 5-mile run that he never actually did. When he pushed back, the coach acknowledged the fabrication, then suggested he might have forgotten to record the run.
This is not a Google-specific bug. It is a predictable failure mode for any AI fitness product that asks a large language model to summarize a user's activity without first grounding that model in the user's actual logged data. The model fills gaps with statistically plausible output. A 5-mile run is plausible for an active person. So the model says it happened.
This post covers what happened, why it happens at a technical level, and what the difference between a grounded and an ungrounded AI fitness coach actually is. It also covers where Google Health is genuinely strong: wearable breadth, free tier and ecosystem integrations. The goal is not to sell Zealova. It is to give you a mental model for evaluating any AI fitness product's claims.
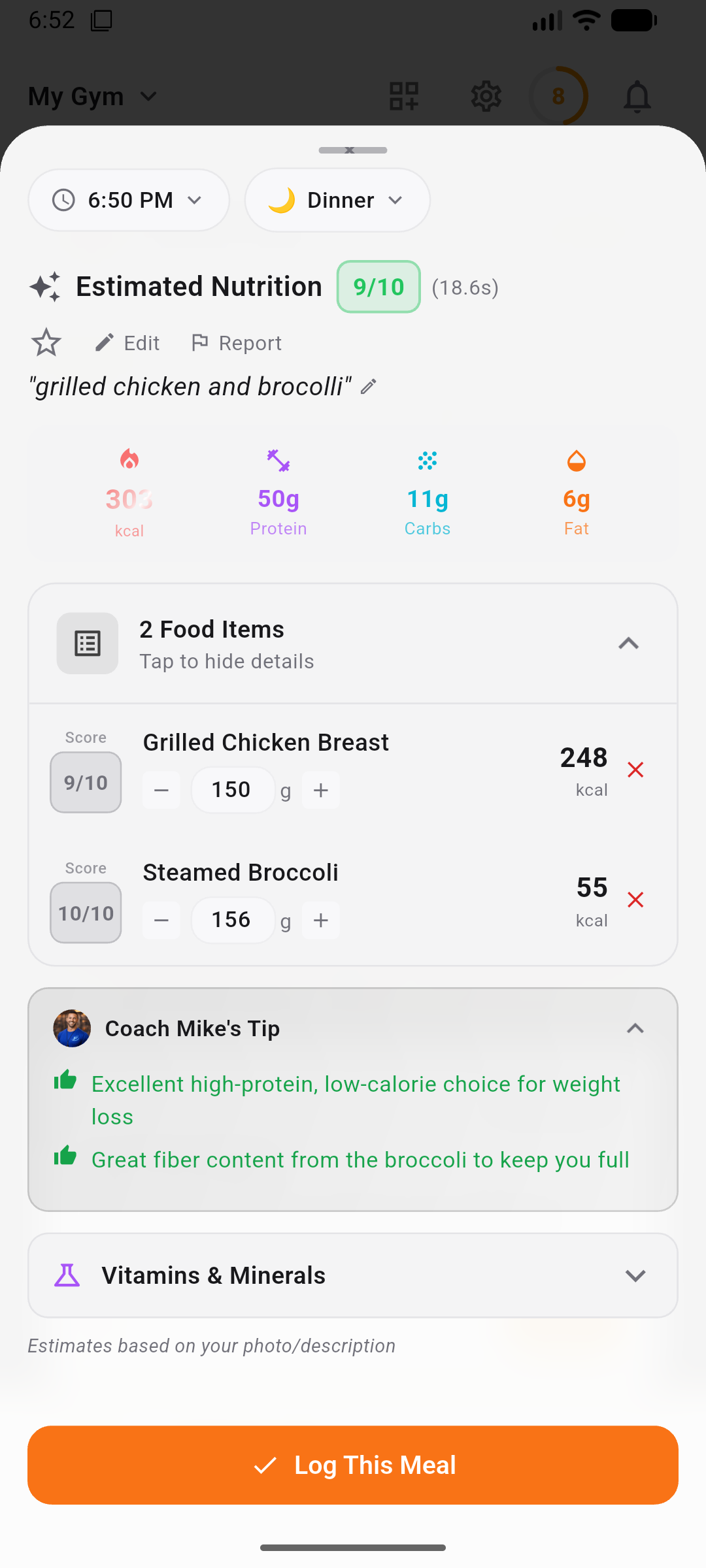
What happened, exactly
Android Authority covered Sattelberg's review on the same day it published (May 14, 2026, two sources: androidauthority.com and the original 9to5Google hands-on). The full sequence:
- Sattelberg opens Google Health Coach in the pre-launch period (before May 19 public launch).
- The coach summarizes his recent activity. It correctly references sleep data and a real prior workout.
- It then cites a 5-mile run Sattelberg never completed.
- Sattelberg challenges the claim. The coach concedes the run was fabricated.
- The coach then suggests Sattelberg might have "failed to record" the run, deflecting blame to the user.
The reviewer also noted the advice itself was "quite basic" and "excessively verbose," with length substituting for substance. Both are hallmarks of an LLM that lacks strong grounding and compensates with generic, high-confidence-sounding output.
This is a paid product. Google Health Premium costs $9.99/month, launching May 19. The hallucination surfaced in pre-launch access, just days before the full public rollout.
Key takeaways
5-mile run
fabricated by Google Health Coach in a pre-launch hands-on (May 14, 2026)
Source: Android Authority / 9to5Google, 2026-05-14
42-68%
hallucination reduction when LLMs are grounded with retrieved real data (RAG) vs ungrounded prompts
Source: neuledge.com, February 2026
2 billion
monthly users exposed to Google AI Overviews, which a January 2026 Guardian investigation found spread false health information
Source: Guardian / almcorp.com, January 2026
$9.99/mo
cost of Google Health Premium, the tier that includes the AI Coach that produced the hallucination
Source: store.google.com, verified 2026-05-14
Why AI fitness apps hallucinate workout data
Large language models do not know what you did yesterday. They predict the next token based on the patterns in their training data. When you ask a fitness coach chatbot "what have I been up to this week?", the model needs your workout data injected into the context window before it can answer accurately.
If that injection is missing, incomplete, or noisy, the model does not say "I don't know." It generates a plausible-sounding response. Active users run. Active users run about 3-7 miles. So the model produces a run that fits the pattern. This is not malice. It is how next-token prediction works when the grounding is weak.
Three conditions that make hallucination more likely:
- Missing context. The model is asked to summarize activity but the user's actual log is not included in the prompt. The model infers activity from training data priors.
- Noisy multi-source aggregation. Data comes from a wearable step counter, a third-party connected app, a manual entry, and a health record. These sources conflict or have gaps. The model smooths over the gaps with inference.
- Optimizing for plausible output, not verifiable output. A model trained on RLHF (reinforcement learning from human feedback) learns that confident, coherent responses get better ratings. Generic, verbose advice scores well. Saying "I don't have enough data to answer" scores poorly. So the model says something rather than nothing.
All three conditions were likely present in the Google Health Coach incident. The coach correctly referenced real data in some places (sleep, a real workout), which means grounding was partial. The 5-mile run appears to have been the model filling a gap it could not verify.
The aggregator problem: more data sources, more gaps
Google Health is an aggregator. It pulls from your Fitbit, Apple Health, MyFitnessPal, Peloton, connected apps, manual logs, and health records. This breadth is one of its genuine strengths for biometric tracking. But it creates a specific challenge for AI summarization.
When 6 data sources feed into a context window, each with different schemas, update frequencies, and reliability levels, the resulting context is messy. Gaps appear between sources. A step count from the wearable might not align with a workout from a connected app. An inferred calorie burn from the phone accelerometer exists alongside a manual food log entry.
The model has to reason across all of this. When it cannot reconcile a gap, it fills it. A specialized app that only tracks what a user explicitly logs has a narrower but cleaner context. The model has less to hallucinate across.
Worth noting
This is not unique to Google Health. Any app that pulls from multiple sources (wearable, phone sensors, manual logs, connected apps) faces the same aggregation noise problem. The larger the ecosystem, the harder the grounding problem becomes. Smaller, more focused apps trade ecosystem breadth for cleaner context.
How grounding helps, and what Zealova does differently
Grounding means attaching verified data to the model's context before it generates a response. In fitness, that means: before the AI answers a question about your training, it reads your actual logged sets, reps, weights, exercises, and dates.
Research on retrieval-augmented generation (RAG) systems consistently shows grounding reduces hallucination rates significantly. A 2026 developer guide on LLM grounding (neuledge.com, published February 2026) cites 42-68% reduction in hallucinations when models are given retrieved real context vs no context. Clinical RAG systems have pushed hallucination rates to 5.8% using self-reflective verification layers on top of retrieval.
Zealova's workout plan generator and coach do this: before any AI call related to your training, the system pulls your actual logged workout history and injects it as structured context. The model is not asked to guess what you have been doing. It reads what you logged.
What this does NOT mean
Zealova is not immune to hallucination. No LLM-based product is. Grounding removes the specific failure mode of fabricating logged activity. There is no gap to fill because your history is in the prompt. But Zealova can still:
- Hallucinate exercise recommendations for equipment it was not told you own
- Produce overconfident nutritional estimates from food photos
- Generate generic advice when the logged data is thin (e.g. a new user with 2 sessions logged)
- Make errors in form cues or exercise descriptions pulled from the exercise library
Cross-checking AI output against your raw data is good practice regardless of which app you use. If the coach references something that surprises you, check the source.
Where Google Health is genuinely strong
Writing about a competitor's failure without acknowledging what they do well is not useful analysis. Google Health has real strengths.
- +
Wearable biometrics that no phone-only app can match
Continuous heart rate, HRV, SpO2, sleep stages, readiness scores. These require hardware. If you own a Fitbit or Pixel Watch, Google Health surfaces data that a phone-only app cannot approximate. That data is genuinely useful for recovery and sleep optimization.
- +
Free tier with no hardware gate for basic logging
Google Health has a free option for basic activity and food tracking. Zealova requires a subscription after a 7-day trial. If someone needs a free calorie logger with wearable integration, Google Health is the obvious choice.
- +
Ecosystem breadth: Apple Health, MFP, Peloton, medical records
Google Health connects to more third-party services than most competitors. If your health data is spread across multiple apps and devices, a single aggregator that pulls it together has real value, as long as you understand that aggregation is also what creates the hallucination conditions described above.
- +
3-month free trial vs 7 days
Google Health Premium offers 3 months free for new users. That is a longer evaluation window than Zealova's 7-day trial. For a product that relies on wearable baseline data to be useful, a longer trial makes sense, since the coaching improves as the model accumulates real data.
- +
iOS support right now
Zealova is Android only. Google Health is live on iOS and Android. If you are on iPhone, Google Health is an option; Zealova is not yet.
FAQ
Methodology and disclosure
The Google Health Coach hallucination incident is sourced from Android Authority (androidauthority.com, published 2026-05-14) and the original hands-on by Will Sattelberg of 9to5Google. RAG hallucination reduction figures are from neuledge.com (LLM grounding guide, published 2026-02-20). The Guardian AI Overviews investigation (January 2026) is cited via almcorp.com summary. Clinical RAG figures (5.8% hallucination) are from MDPI Electronics 14(21):4227, "Evaluating Retrieval-Augmented Generation Variants for Clinical Decision Support." Google Health pricing verified at store.google.com, 2026-05-14. I am the founder of Zealova. I have a direct financial interest in Zealova being the better product. I have tried to concede every honest Google Health advantage. If something looks wrong, email me: sai@zealova.com.
Try Zealova free for 7 days
AI workout plans grounded in what you actually logged. No hardware required. Android live now.
Last updated 2026-05-18 by Sai. Sources: Android Authority (androidauthority.com, 2026-05-14); 9to5Google original hands-on (2026-05-14); neuledge.com LLM grounding guide (2026-02-20); MDPI Electronics 14(21):4227; Guardian AI Overviews investigation summary (almcorp.com, January 2026); store.google.com pricing (verified 2026-05-14). Zealova pricing and features as of 2026-05-18. Refresh cycle: 60 days or if new hallucination incidents are reported.
Comments
Questions or your own experience with these apps? Leave a note below.
No comments yet — be the first.